
Tiếp theo phần 1 ở đây (https://sharenha.com/bi-kip-va-meo-thi-ielts/bi-kip-reading/chien-thuat-lam-4-dang-bai-matching-chac-chan-ra-thi-trong-ielts-reading/) thì ở bài này mình sẽ tìm hiểu 2 dạng bài Matching còn lại nhé, cho đủ bộ Tứ quý kk. Chiến thuật luôn là vô dụng nếu bạn không tập luyện nó đến mức thuần thục, biến nó thành thói quen làm bài, đi sâu vào tâm thức luôn nhé.
I. Dạng bài Matching features trong IELTS Reading
🌈 Là dạng bài xuất hiện dưới dạng câu hỏi ‘Which paragraph contains the following information?‘
🌈 Mức độ khó: gây hoa mắt nếu như bỏ qua các chi tiết nhỏ của bài đọc, đòi hỏi khả năng scan siêu kĩ



What? (Matching features là gì?)
Matching: nối, Features: Các đặc điểm. Dạng bài này yêu cầu thí sinh nối các đặc điểm cho sẵn với người hoặc vật hoặc địa điểm … liên quan.
Các đặc điểm có thể là Statements (khẳng định), Ideas (ý kiến) hay Theories (Lý thuyết)
Dạng bài này có thể được coi là dạng dễ kiếm điểm nhưng chúng ta cũng nên rất cẩn thận khi làm vì:
- Dễ: Phần Scanning khá ngon, vì tên người/vật/địa điểm thì nhường là tên riêng nên sẽ được viết hoa hoặc ko thể paraphrase được (tên 1 loài cây, 1 con vật,…) => ngay lập tức scan được vị trí cần tìm thông tin.
- Cẩn thận: Vì scan dễ rồi nên thường các statements sẽ được paraphrase “mạnh mẽ”, và nhiều statements thì khá giống nhau=> đôi khi tìm được vị trí có thông tin để trả lời rồi mà vẫn làm sai => đọc kĩ và tránh bẫy
VD: Nối tên nhà khoa học và khẳng định họ đã đưa ra. (Ảnh 1)

When? (Khi nào chúng ta gặp dạng bài này?)
Tần suất xuất hiện của dạng bài này khá cao, hầu như trong 5 cuốn Cam mới nhất, ít nhất có một Test có dạng bài này => như vậy, khả năng xuất hiện trong bài thi thật cũng khá lớn.
Như các bạn biết, mỗi một Passage trong bài IELTS READING sẽ gồm từ 13-14 câu hỏi, 13-14 câu đó sẽ được chia thành nhiều dạng khác nhau. Dạng Matching Features có thể được tìm thấy ở bất kì một Passage nào, tuy nhiên, nó hay xuất hiện sau những dạng câu hỏi như:
- Information Matching (Thông tin này nằm ở đoạn nào),
- Matching Heading (Tìm tiêu đề cho đoạn) hay
- Summary Completion (Hoàn thành tóm tắt).
Nắm bắt được điều này rất quan trọng vì nó giúp chúng ta giải quyết dạng bài này một cách nhanh hơn (giải thích trong phần How)
VD: Trước câu 4 – 9 phía trên, câu 1 – 3 của Passage này là dạng Information Matching (Ảnh 2)

How? (Chúng ta giải quyết dạng bài này như thế nào?)
Bước 1: Như đã nói ở phần When, dạng bài này thường xuất hiện sau các bài yêu cầu thí sinh phải Scan qua cả Passage => trước khi đọc bất kỳ một Passage nào, nên lướt qua tất cả 13-14 câu hỏi để xem có dạng Matching Features không. Như ví dụ trên, khi thấy câu số 4-9 là dạng Matching Features và yêu cầu nối tên các nhà khoa học với các khẳng định của họ, thì ngay khi Scan bài văn để trả lời câu 1 – 3 ta phải đồng thời khoanh tròn luôn tên của tất cả các nhà khoa học xuất hiện trong bài. Việc này nhằm mục đích khi làm tiếp câu 4-9 ta không phải tìm lại từ đầu.

Bước 2: Đọc các Features và gạch chân từ khóa. Các từ khóa sẽ thường xuất hiện dưới dạng từ đồng nghĩa.
VD: Feature: Q8: Governments can help to reduce variation in prices
Text: Sophia Murphy, senior advisor to the Institute for Agriculture and Trade Policy, suggested that the procurement and holding of stocks by governments can also help mitigate wild swings in food prices by alleviating uncertainties about market supply.
*reduce variation in prices = mitigate wild swings in food prices => 8B
Bước 3: Nối các đặc điểm với người/vật liên quan.
Chú ý:
Đôi khi một người/vật/địa điểm… sẽ có tới 2 đặc điểm, còn có những người/vật/địa điểm lại chẳng có đặc điểm nào. (Những bài nào có đề bài là You can use any letter more than once thì khả năng cao là có 1 đáp án xuất hiện 2 lần)
VD: Ở bài trên, ta có đáp án 8B. Ngoài ra, ta thấy câu 5 cũng có đáp án là B vì:
Feature: Q5: Farmers can benefit from collaborating as a group
Text: According to Murphy, ‘collective action offers an important way for farmers to strengthen their political and economic bargaining power, and to reduce their business risks.’
Tên người/vật/địa điểm… đôi khi sẽ được rút gọn như câu trên Sophia Murphy được viết thành Murphy.
Bây giờ chúng mình hãy cùng làm nốt các câu còn lại nhé.

I. Dạng bài Matching Names trong IELTS Reading
🌈 Là dạng bài nối tên riêng với ý kiến, quan điểm, lời nói của người đó
🌈 Mức độ khó: dễ nhất trong số các dạng bài nối kể trên =)) Tuy nhiên nó lại khó ở khía cạnh các quan điểm của người nói thường được paraphrase 360 nên nếu không đọc hiểu mà đọc theo kiểu nắm key word nối bừa thì cũng dễ ngỏm
Đã bao giờ bạn rơi vào tình thế tìm được thông tin rồi nhưng vẫn làm sai dạng bài này chưa? Nếu có là câu trả lời thì bạn đừng bỏ qua post này nhé 😃 Trong post ngày hôm nay, mình sẽ chia sẻ cho mọi người 2 techniques để giải quyết hiệu quả dạng bài matching names này
1. Làm theo thứ tự bạn muốn
Các câu hỏi trong bài đọc IELTS đa phần đều được sắp xếp một cách có chủ đích, người ra đề muốn chúng ta làm những câu hỏi như matching headings hoặc sentence completion trước để có cái nhìn tổng quan nhất về bài đọc, sau đó mới đến những câu hỏi về chi tiết như matching phrases.

Đối với dạng matching names, mặc dù nó được coi là dạng câu hỏi về details, tuy nhiên chúng ta có lợi thế là câu hỏi chứa tên riêng – đây chính là vũ khí giúp chúng ta scan thông tin nhanh hơn và có thể tận dụng làm dạng bài này bất cứ lúc nào bạn muốn hoặc làm bất cứ tên riêng nào trước mà không phải theo bất cứ thứ tự nào.
2. Chú ý tới kĩ thuật paraphrase
Sau khi đã scan được tên riêng trong bài thì nhiều bạn lại gặp phải vấn đề khác, đó là tìm ra được tên riêng nhưng vẫn chọn sai đáp án. Đây là lúc chúng ta cần chú ý tới technique số 2, để ý tới các cụm từ được paraphrase trước và sau tên riêng đó để chọn ra đáp án đúng.
—
Trăm nghe không bằng một thấy, chúng mình hãy cùng nhau luyện tập 5 câu hỏi trích từ quyển sách Cam 10 – Test 2 – Passage 2 Gifted children and learning sau đây nhé, câu 18-22:
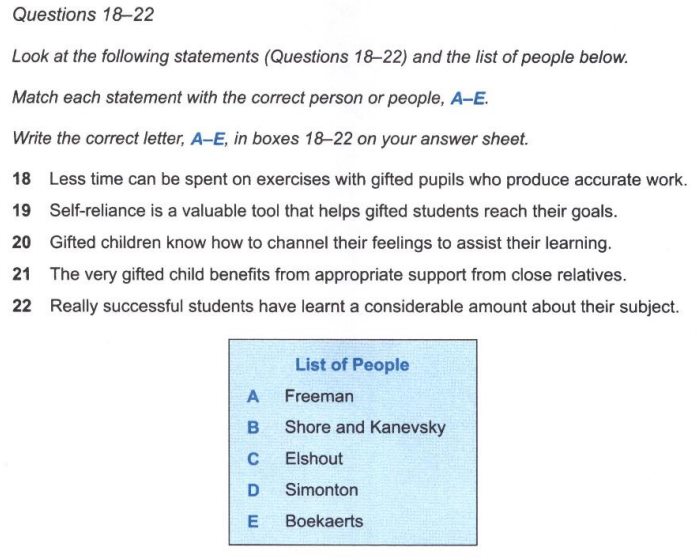



Đầu tiên, chúng ta có thể dễ dàng xác định những tên riêng trong bài nằm ở những paragraph nào của bài đọc, trong trường hợp này thì tên Freeman nằm ở đoạn A, Shore and Kanevsky nằm ở đoạn C, Simonton và Elshout nằm ở đoạn E, và Boekaerts’ nằm ở đoạn F
Tiếp đến, chúng ta sẽ đi scan các thông tin nằm gần những tên riêng đó và tìm các cụm từ được paraphrase sẽ ra được đáp án, cụ thể như sau:
Gifted pupils = the gifted
Produce accurate work = make few errors
Less time spent on = shorten the practice
Câu 19: đáp án D
Self-reliance = independence
Reach their goals = reach the highest levels of expertise
Câu 20: đáp án E
Gifted children = highly achieving children
Assist their learning: bao gồm control their environment, improve learning efficiency, increase learning resources
Câu 21: đáp án A
Close relatives = a very close positive relationship
Appropriate support = educational backup (interactions with parents)
Câu 22: đáp án C
Know a great deal = learnt a considerable amount
Their subject = a specific domain



